




Introduction
This week we will about data types in Rust. We will check the existing primitive data types in Rust, learn how to create our own using structs and talk about how Rust handles Sum Types through Enums.
I was planning to also talk about control flow, but this post grew too large and I’ll only talk about types.
Types
Being a strongly typed language, every value must have a type. A types tells the Rust compiler what is the format of the data, which values it can have and and which it cannot.
Rust exposes a complete set of primitive types with different sizes. Most numeric values follow the naming convention <data-type><size>. For instance, the type u8represents a unsigned integer of size 8, while a i32represent a signed integer of size 32. Let’s check them all.
Integer Types
An integer is a number without a fractional component. Rust provides 12 different options for such types, varying according to signedness and size, ranging from 8 to 128 bits (with one exception). The following table extracted from [Data Types — The Rust Programming Language] shows these values.
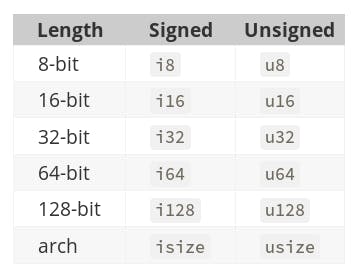
As you can see, there’s a huge range of options.
Two cases are special in this table, isize and usize. The size of these is architecture dependent. These types are used to represent indexing information on collections and vary according to the architecture the computer is compiled on. It will be 64 bits on a 64-bits architecture and 32 bits in a 32-bit architecture. usize roughly map to the size_t type in C++.
A special note should be taken regarding overflow. program compiled in debug mode, numerical operations are checked, so if a overflow occurs the application is terminated with an error. The release mode does not include such checks.
If you want overflowing types you can use std::num::Wrapping.
Floating Point Types
Floating point types represents numbers with a fractional component. Rust provides two such types, the f32 type, which represents a floating point number with 32 bit size and f64 type which represents a more precise, 64 bit size. On modern architectures operations on f64 are roughly the same speed as f32, but with more precision. The floating point types follow the IEEE 754 standard, with f32being a single-precision float and f64 being double precision.
Boolean Type
The boolean type is inhabited by only two possible values: true and false. Its main usage is for control flow of a program, which we will be discussing on the next post. It is represented by the booltype in Rust.
Character Type
A charis a special type, representing a four byte (32 bit) Unicode Scalar Value. Notice that this means it does not map to a charin C/C++, which is usually 8 bits. A common intuition to have is that a char represents a letter. This does not mean that it can only represent a letter though. While it maps all letters in the ASCII set as expected, it can represent much more, such as accented letters, emojis, Arabic, Chinese, Japanese and other languages “letter set”.
Unicode is a really complex topic to get into and we don’t have time to go into right now, but we will talk a little more about it once we talk about the Stringtype.
Structs
Structs is one way of doing type aggregation. It is a form a Product Type, where each of the fields are tagged by a name. It maps roughly to a struct in C, but not exactly like a class in OOP languages. On the next post we will see how to group data and behavior together in Rust, but for now it is easier to think of a struct as just an aggregation of data.
Defining a struct is again similar to C:
struct Point {
x: f64,
y: f64,
}
Constructing a value is done by giving a value for each field. Field access is done by name:
let point = Point { x: 0.0, y: 0.0 };
println!(“x: {}, y: {}”, point.x, point.y);
Tuples
The Tuple types represents another way of aggregating data of possibly distinct but defined types. A simple way of thinking about it is that a Tuple is an array of a fixed size (this size is called the “arity” of the tuple) where each entry might be of a different, but predefined type. Tuples are similar to structs in that it represents a Product Type. But different from structs, fields do not have names and are accessed through their index. We see these concepts in the following code snippets:
// A tuple of airty 3, where the third element is another tuple of arity 2
let x: (i32, f64, (i32, f64)) = (1, 2.0 (3, 4.2));
// Access is done through the index of the entry
assert_eq!(x.2, (3, 4.2))
We can do destructuring of tuples, making it easy to access some partial information about the tuple. This will come in handy for pattern matching on tuples on our next topic (you can also destructure in structs! We will take a look at that when we talk about pattern matching).
let x: (i32, f64, (i32, f64)) = (1, 2.0 (3, 4.2));
// Destructure the tuple, so we can access each entry by a name
// Notice that the destructuring nests, so we can extract information of nested tuples
// If we want to ignore some information we can just use `_` so we don’t give a name
// to that field of the tuple
let (a, _, (_, d)) = x;
println!(“{} {}”, a, d); // prints 1 4.2
We can create our own tuple based types. This gives a syntax similar to constructors in other languages when building these new types:
// Creates a new type that wraps a pair of f64
struct Point(f64, f64);
// We create instances by calling the type name with the parameters
let my_point: Point = Point(1.0, 2.0);
// Access is done through indexing
println!(“{}”, my_point.0); // prints 1.0
// As with normal tuples we can also destructure it
let (x, y) = my_point;
println!(“{} {}”, x, y);
A common usage of tuples is the “New Type” pattern. This is a common pattern in Domain Driven Development, where we give a type to each aspect of our application. Say we have a database where we want to associate names and addresses. We could just pass Strings around, but Strings are not a name or an addresses (though it might be its representation in memory). Using the New Type pattern we create a wrapper type so we can reason about our Domain and our code in the same “language” (called ubiquitous language in DDD):
struct Name(String)
struct Address(String)
fn register_in_database(name: Name, address: Address) {…}
Enums
While structs and tuples, which are Product Types, are one side of the Algebraic data type coin, Enums represents the other side, being a Sum Type. Enums represent the “one of” abstraction, and are declared by giving each of it’s possible values a name:
enum Shape {
Rectangle,
Circle
}
We can construct the value by referring to its name. We can also evaluate which of the possible values the enum holds by using a match expression:
let my_shape: Shape = Shape::Rectangle;
match my_shape {
Shape::Rectangle -> println!(“Rectangle!”),
Shape::Circle -> println!(“Circle!”)
}
We will go more in depth about match expressions on the next post when we talk about pattern matching.
What makes Enums even more powerful is that each of the cases may hold a different set of Product Types (tuples or structs):
enum Shape {
Rectangle {
lower_left: Point,
upper_right: Point
},
Circle {
center: Point,
radius: f64
}
}
In memory, the size of a enum value will always be the size of the “largest” possible value, so some care must be taken for performance reasons. For instance, supose we have the following enum:
enum Shape {
OptionA(AHugeDataStruct),
OptionB(f64)
}
If most of the time objects of OptionB value is created, even though it looks like it should be 64 bits in size, it ends up taking the size of AHugeDataStruct.
There are a bunch of special optimizations around enums and it’s size that I might do a short post about in the future.
Arrays
Similar to tuples, arrays group multiple values into one value type. Where it differs is that all values must have the same type and the size is part of the type signature. This means that the size of the array must be known and is static. The main use of arrays is when you wish to allocate a collection of values on the stack. Rust also provides collections with dynamic size, but these values allocate memory on the heap. The type declaration of a array follows the format [<data-type>; <size>].
Access is done through indexing. Indexing into arrays is always checked. This means that at runtime Rust will always check if the value you are trying to access is withing the bounds of the array. If it is not a runtime error will be thrown. This check does incur some performance cost, but most of the time it is small. If you are sure of what you are doing the language does provide a scape hatch using unsafe code. We will talk about that in a future post.
// Creating an array
let x: [i32; 5] = [1, 2, 3, 4, 5];
assert_eq!(x[0], 1)
let boom = x[100]; // Runtime error
Slices
A slice represents a view into a contiguous sequence of elements in a collection. There are two main forms of slices, String slices which we will see in the next topic and array slices.
// Creating an array
let x: [i32; 5] = [1, 2, 3, 4, 5];
// We slice into the elements from the second to the third elements
let slice: &[i32] = &x[1..3];
// We can index into the slice
assert_eq!(slice[0], 2);
assert_eq!(slice[2], 4);
// Bounds checking also works with slides
slice[100];
The syntax <beggining>..<end> creates a range of values from the beggining value (inclusive) to the end value (exclusive). Slices are useful as a “view” into the data, without needing to copy it.
This is the first time we are seeing one of the most powerful tools in Rust, the & symbol which stands for a “reference to”. For now you can think of it just as a pointer in other languages. You can read the type &[i32] as “a reference to a array of i32s”. Another point to take note is that the indexing on the slice is relative to that slice’s bounds, not the source data. This can be better explained in an image:
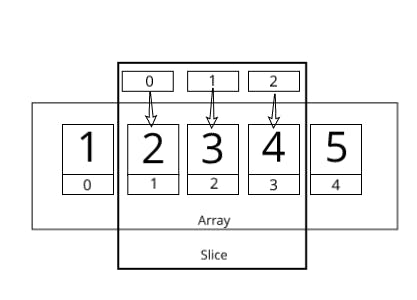
Strings
Strings are one of the most common data types in any language, and is no different in Rust. It represent some form of text, such as a file’s content or an user input. The language provides two representations for strings, the String type and the strtype (usually used as a reference, &str which represents a string slice). A string slice can be seen as a view (read only) into a the raw data of a String. Strings can be easily converted into &str values. It is usually more efficient to pass the slice around then the whole String. This is the same philosophy of the new std::string_viewtype in C++17.
// This is a string slice
let my_string_slice: &str = “Hello World!”;
// We can create strings from string slices
let my_string: String = my_string_slice.to_string();
// Or create the string with the “from” conversion method
let my_string2: String = String::from(“Hello Universe!”);
// If a function takes a &str
fn my_fn(value: &str) {…}
// We can pass it our string reference
// Under the hood there’s a trait called deref
// That does some magic to us.
// We’ll talk about that on the next post
my_fn(&my_string);
Strings in Rust are UTF-8 encoded by default and, roughly speaking, are internally represented by a Vector of u8s (Vec<u8> in Rust’s notation). Notice that one might find it confusing since the char type is 32 bit in size. This is because the UTF-8 format “compacts” the String representation so the most common case ASCII can be represented in just one u8 value (technically, half of a u8 since there are 128 ASCII values, which are mapped directly into UTF-8), while more complex “letter” representations group sequences of up to 4 u8s to encode its value.
This means that you can’t directly access String data through indexing. After all it would not be clear what you are trying to access. Is it the underlying u8 value? Or maybe you specifically want to access the char that might be composed of a cluster of u8s? If you know specifically what you want to access, the methods bytes and chars will give you iterators into each representation.
let my_string = “Hello World”;
assert_eq!(my_string[0], ‘H’); // error!
assert_eq!(my_string.chars().nth(0), ‘H’); // Ok!
If you need a String representation that is closer to the C/C++ style, you can use the type CString.
PS: Such a data representation is biased towards western languages for historical reasons.
Conclusion
Now that we know how to write our own data types we can start to have some real fun. On the next post we will talk about control flow and traits, which is a abstraction to represent the functionalities of a particular type.
The following post will have a discussion on Rust’s view on Object Oriented Programming and how to map what is now the most common programming paradigm into Rust’s way of thinking.
See you then!